“Why Does ChatGPT ‘Delve’ So Much?”: FSU researchers begin to uncover why ChatGPT overuses certain words

With nearly 70 million monthly ChatGPT users in the U.S., large language models and chatbots are now used for everyday activities, corporate campaigns, research methods and more. However, even with this rapid expansion, how large language models are trained and why they respond to prompts the way they do remains unclear.
A team of two Florida State University researchers, a computational linguist and a philosopher of science, is launching a novel research area to investigate why ChatGPT responds the way it does. Their study, “Why Does ChatGPT ‘Delve’ So Much? Exploring the Source of Overrepresentation in Large Language Models,” was published in the Proceedings of the 31st International Conference on Computational Linguistics in January and is the first scientific evidence pointing toward why ChatGPT tends to overuse certain words.
“We were inspired to conduct this study after seeing discussions online from scholars who noticed different abstracts overusing very specific words,” said Zina Ward, assistant professor in the Department of Philosophy and Interdisciplinary Data Science Master’s Degree Program faculty. “In addition to determining which words were being overused by ChatGPT, our research sought to understand how this overuse comes about. These language models are so new that there’s not much other research looking at their use of language.”
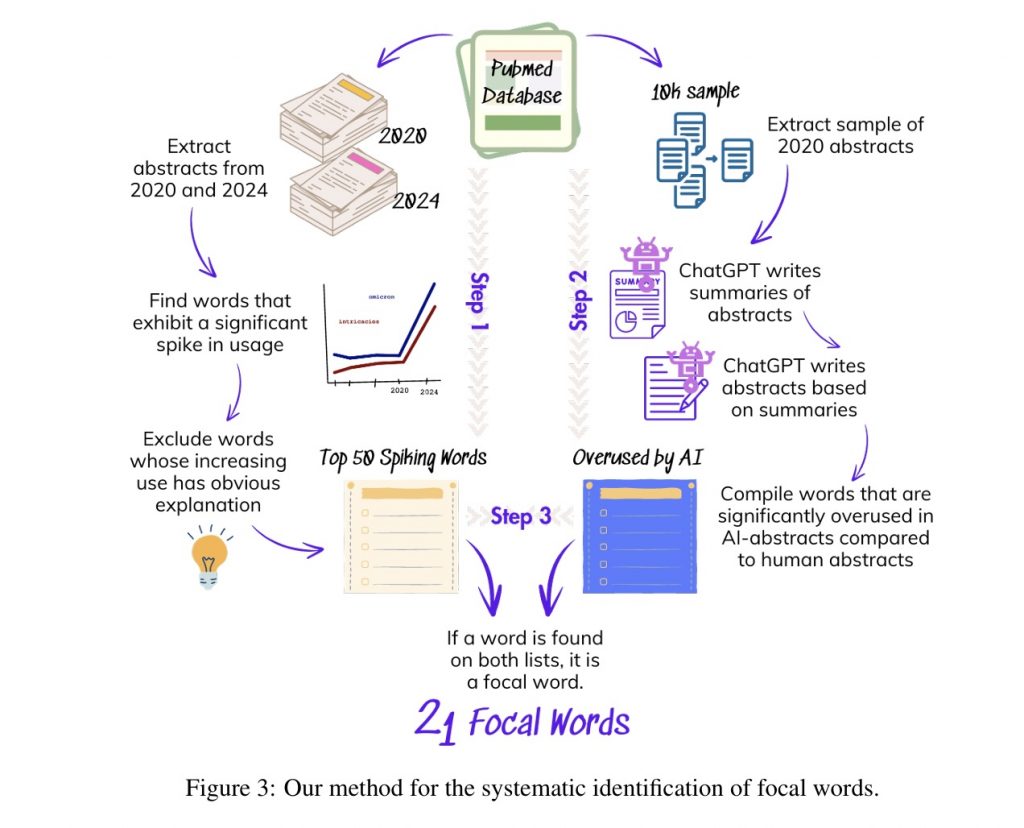
Tom Juzek, an assistant professor of computational linguistics in the Department of Modern Languages and Linguistics also connected with the Interdisciplinary Data Science Master’s Degree Program, and Ward provided a rigorous procedure for identifying 21 words whose frequency in scientific abstracts had spiked unusually high in the past four years with no obvious explanation. The duo found that human preference for some of these words was influenced by their overuse.
“We’ve observed unprecedented language change in the past four years or so,” said Juzek, who worked in artificial intelligence and technology in the private sector before transitioning to academia. “It was significant that so many people had noticed this overuse. It’s normal for one or a couple of words to shift in usage over the years, but dozens of words drastically increasing in frequency is odd. Our work, which is at the nexus of linguistics, computational linguistics, computer science, data science, philosophy and ethics, has wide implications and analyzes the interplay between technology and human language and how technology affects our languages.”
The team first compared human-written scientific abstracts from 2020 and 2024 to identify which words were in much wider use in 2024 compared to four years earlier. They then developed a database of human-written scientific abstracts published in 2020 and asked ChatGPT to rewrite all of them, later comparing the two versions of each abstract to determine which words are more common in ChatGPT-generated abstracts than in human-written abstracts. The team found that many of the words that had recently spiked in use were the same words being overused in ChatGPT-generated abstracts.

“After we determined that the words used more frequently in scientific abstracts are the same words being overused by large language models, we ran an online experiment emulating the procedures that tech companies use to help their models learn from human preference and human feedback,” Juzek said. “We presented participants with two options: one abstract with many overused buzzwords and AI-like language such as words like ‘delve,’ ‘realm’ and ‘intricate,’ and another abstract without these buzzwords. We queried hundreds of participants to understand how the buzzwords affect human preference of the words, and we found that participants reacted much more negatively to the word ‘delve’ than other buzzwords.”
Another major part of the study included a model comparison and measures of perplexity, which quantifies how “surprised” a language model is by a given sequence of words. The team utilized two different large language models, the base version and the enhanced version of Meta’s Llama model, to determine if either model would be “surprised” by a piece of text.
“We wanted to see whether the version of Llama that’s already been trained on human preference data uses more of these buzzwords than the base version,” Ward said. “We found that the enhanced model was less surprised by abstracts containing the buzzwords than the base model that had not been trained on human preference data. This suggests that human preference data is a source of the lexical preferences — word choices — of these large language models.”

In January, Juzek traveled to the 31st International Conference on Computational Linguistics in Abu Dhabi, United Arab Emirates, to present this work at one of the field’s most prestigious symposia. By using tools and methodologies from computational linguistics, the team plans to continue their investigation of the highly complex language models going forward.
“The rapid growth of generative AI is having a profound influence on all corners of society,” said Sam Huckaba, dean of the College of Arts and Sciences. “The leading-edge research of Tom and Zina is critical as we move forward and is especially relevant to the academic community as we integrate this technology into our professional lives.”
To learn more about research conducted in the Department of Modern Languages and Linguistics, visit mll.fsu.edu. For more on work in the Department of Philosophy, visit philosophy.fsu.edu. To learn more about the Interdisciplinary Data Science Master’s Degree Program, visit datascience.fsu.edu.